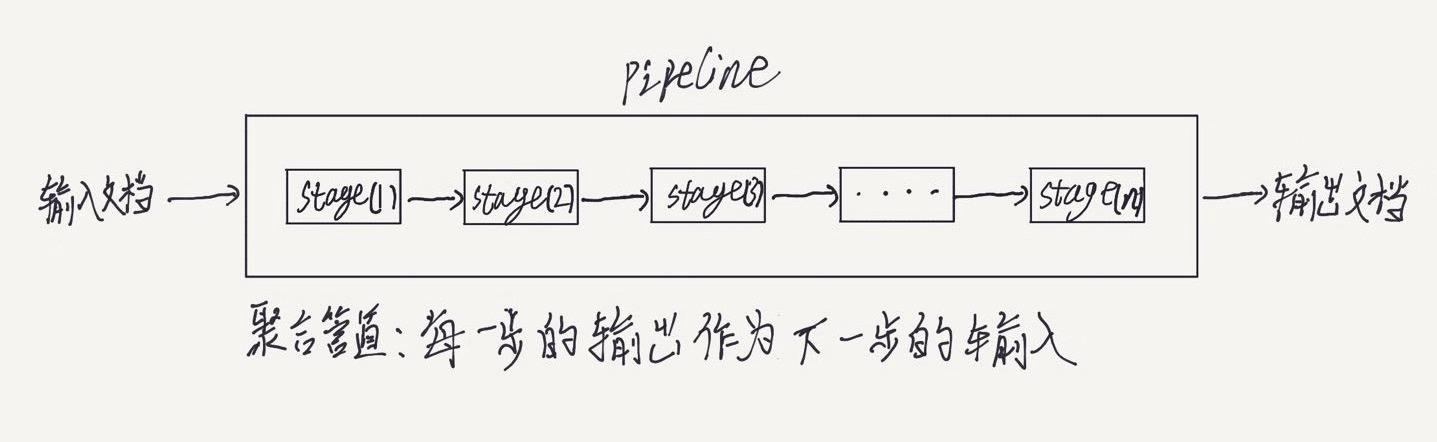
聚合管道是一个基于数据处理管道概念建模的数据聚合框架,文档进入一个多阶段的处理管道,该管道最终将其转换为聚合后的结果。
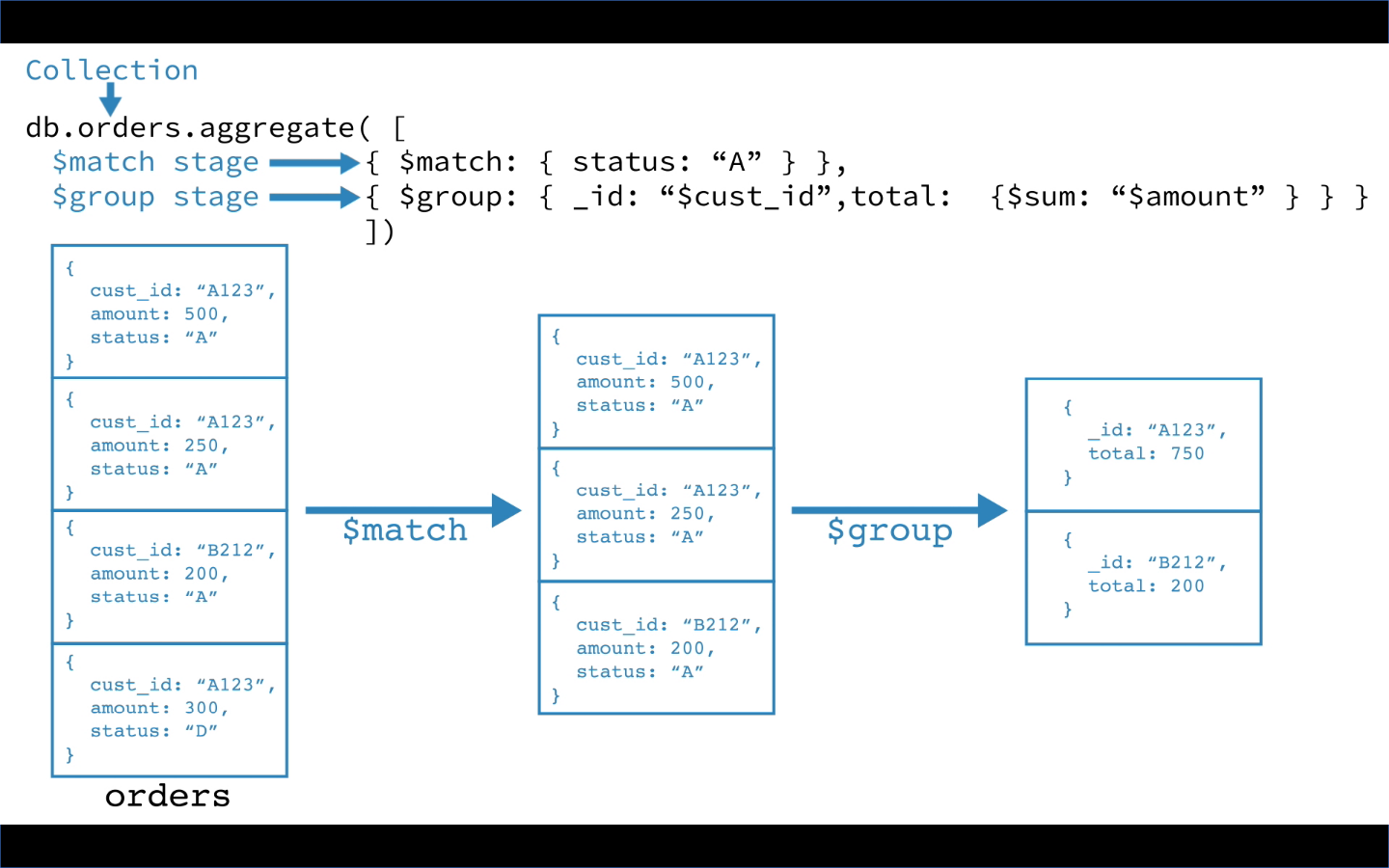
下面的例子来源于官方文档。第一阶段,$match按status字段来过滤文档,并把status字段值为A的文档传递到下一阶段;第二阶段,$group将文档按cust_id进行分组,并针对每一组数据对amount进行求和。
db.orders.aggregate([
{ $match: { status: "A" } },
{ $group: { _id: "$cust_id", total: { $sum: "$amount" } } }
])
管道
聚合管道包含很多步骤,每一步都会将输入的文档进行转换,但并不是每个阶段都一定需要对每个输入文档生成一个输出文档,比如某些阶段可能生成新的文档或者过滤掉文档。
除了$out、$merge、$geoNear外,其它的阶段都可以在管道中多次出现,更加详细的内容可以查看 Aggregation Pipeline Stages。
管道表达式
一些管道阶段采用表达式作为操作元,管道表达式指定了要应用到输入文档的转换,表达式自己是一个文档结构(JSON),表达式也可以包含其它的表达式。
表达式仅提供文档在内存中的转换,即管道表达式只能对管道中的当前文档进行操作,不能引用来自其他文档的数据。
写聚合表达式式建议直接参考官方文档,下面列出一些我收集的案例,供深入理解使用。
案例一:将对象数组转换为单个文档
// 转换前
{
"_id": "10217941",
"data": [
{
"count": 2,
"score": "0.5"
},
{
"count": 6,
"score": "0.3"
},
{
"count": 5,
"score": "0.8"
}
]
}
// 转换后
{
"_id": "10217941",
"0.3": 6,
"0.5": 2,
"0.8": 5
}
需要说明的是,如果上面data属性中的数据格式为{"k": "0.6", "v": 5},那么下面的聚合表达式就不需要$map,这一点可以查看 $arrayToObject。这个案例的难点在于score中有小数点,这个小数点会让聚合表达式懵逼的。
db.collection.aggregate([
{
"$addFields": {
"data": {
"$arrayToObject": {
"$map": {
"input": "$data",
"as": "item",
"in": {
"k": "$$item.score",
"v": "$$item.count"
}
}
}
}
}
},
{
"$addFields": {
"data._id": "$_id"
}
},
{
"$replaceRoot": {
"newRoot": "$data"
}
}
]);