参考:
汉语言处理包 HanLP:https://github.com/hankcs/HanLP
中文文本分类:https://github.com/gaussic/text-classification-cnn-rnn
农业知识图谱:https://github.com/qq547276542/Agriculture_KnowledgeGraph
事实三元组抽取:https://github.com/twjiang/fact_triple_extraction
中文自然语言处理相关资料:https://github.com/mengxiaoxu/Awesome-Chinese-NLP
开放中文实体关系抽取:http://www.docin.com/p-1715877509.html
自 2012 年 Google 提出“知识图谱”的概念以来,知识图谱就一直是学术研究的重要方向,现在有很多高校、企业都致力于将这项技术应用到医疗、教育、商业等领域,并且已经取得了些许成果。Google 也宣布将以知识图谱为基础,构建下一代智能搜索引擎。
现在已经可以在谷歌、百度、搜狗等搜索引擎上面看到知识图谱的应用了。比如在 Google 搜索某个关键词时,会在其结果页面的右边显示该关键字的详细信息。在几个常用的搜索引擎中搜索知识时,返回的答案也变得更加精确,比如搜索“汪涵的妻子”,搜索引擎会直接给出答案“杨乐乐”,方便了用户快速精准的获取想要的信息。不过目前的搜索引擎只有少部分搜索问题能达到这种效果。
关于知识图谱是什么,我想就不用介绍了,这种通过搜索引擎就能轻松得到的结果写在这里有点浪费篇章,并且我对知识图谱的理解也不深,不敢夸夸其谈,只是把自己这一段时间以来的工作做一个总结。
本文只相当于以经济责任审计这一特定领域构建了一个知识图谱,仅仅是走了一遍流程,当作入门项目,构建过程中参考甚至抄袭了别人的很多方法与代码,末尾都会给出参考的项目等等。
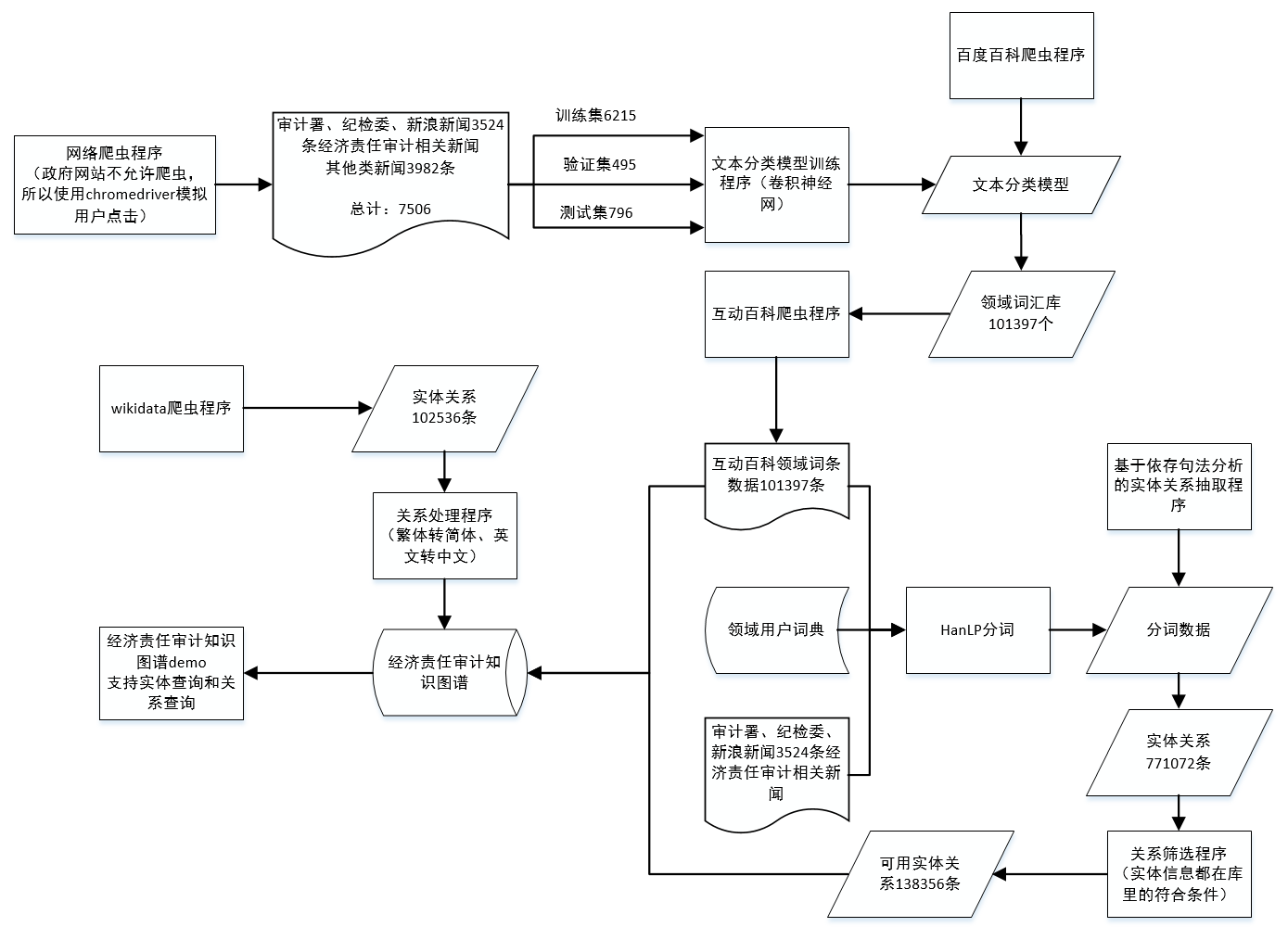
上图是我构建经济责任审计知识图谱的流程,看起来很繁琐,但只要静下心看,个人觉得相对还算清晰,箭头都有指向。下面就一步一步进行说明。
数据获取
数据获取主要分为两部分数据,一部分是新闻类数据,我把它用作文本分类模型的训练集;另一部分是实体数据,为了方便,我直接把互动百科抓取的词条文件作为实体,省了属性抽取这一环节。
因为本文构建的是一个经济责任审计领域的知识图谱,所以作为文本分类模型训练集的数据也应该是经济责任审计领域的。这里主要抓取了审计署、纪检委、新浪网的部分新闻。
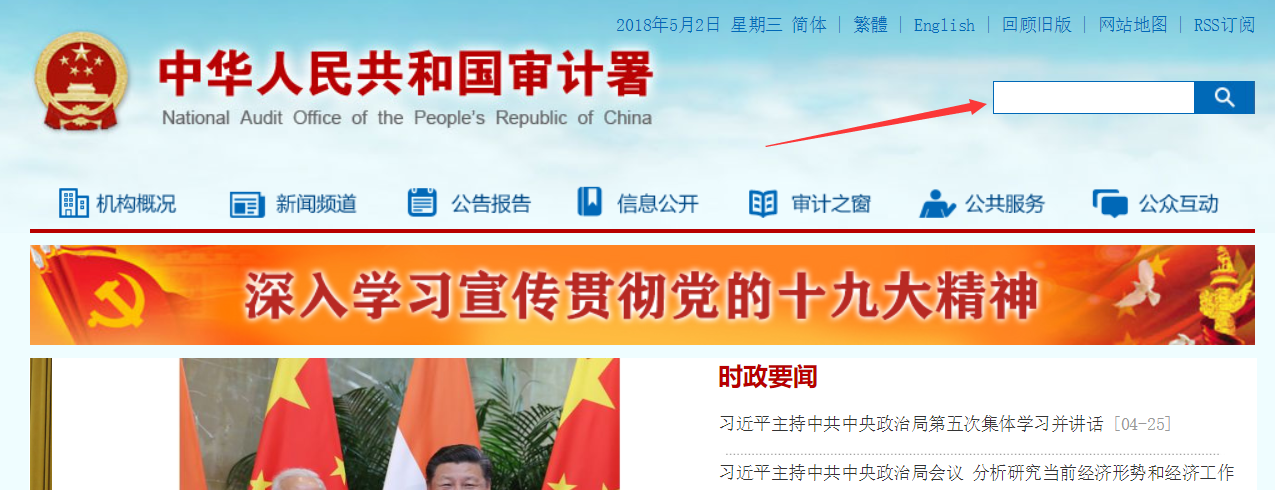
像上面的图一样,新闻类网站一般都有搜索框,为了简单,所以我直接用搜索框搜索“经济责任审计”,然后从搜索结果中抓取新闻数据,即认为是经济责任审计相关的文本。抓取新闻类网站使用了 chrome 模拟用户进行访问。最终获得了 3500 多条新闻文本。
领域词汇判定
领域词汇判定,本文构建的不是开放领域的知识图谱,所以需要采用一种方法来判定所抓取的内容是否属于经济责任审计领域。领域词汇本文的方法实际上是领域句子判定,直接使用了大神的项目。CNN-RNN中文文本分类,基于tensorflow。也看到有人通过改进逻辑回归算法,在进行领域词汇的判定。
我判定领域词汇的逻辑是这样的,一个词语即使是人类也不一定能确定它是否属于经济责任审计领域,但是每个词语都会有它的含义解释对不对,一个词语的解释就是一段话。我用网上的新闻训练出一个判断一段话属于哪个领域的模型,然后把词语的解释放到模型了里面去,如果模型给出的结果是属于经济责任审计领域,那则认为这个词语属于经济责任审计领域。
实体关系抽取
知识图谱的基本单位为(实体1,关系,实体2)这样的三元组,实体是直接从互动百科获取的词条,关系由两部分组成,一部分来自 wikidata 所提供的关系,这一部分直接从 wikidata 爬取即可得到,另一部分使用的是基于依存句法分析的开放式中文实体关系抽取,已经在前面的文章发过了。
知识存储
有了实体和实体关系,那么把这些数据进行筛选,然后入库,通过直观的页面展示,就可以了。这里使用的数据库是 neo4j,它作为图形数据库,用于知识图谱的存储非常方便。知识的展示使用了别人的项目,仅仅是把里面的数据换掉了而已,感谢大神的无私。
当然你也可以选择使用关系型数据库,因为我做的经济责任审计知识图谱不够深入,所以做到最后展示的时候,发现其实用我比较熟悉的 MySql 更好,相比 NOSql 我更熟悉关系型数据库,而且 MySql 有更大的社区在维护,它的 Bug 少、性能也更好。
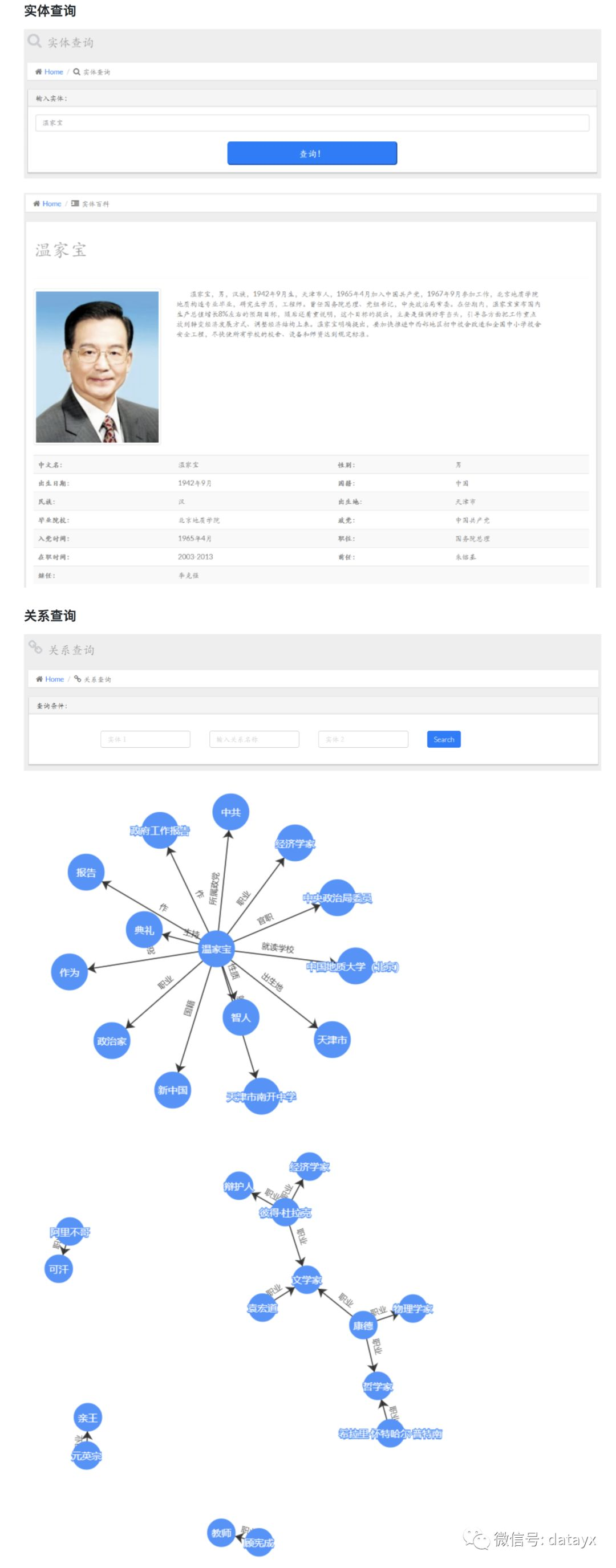
最后放几张效果图

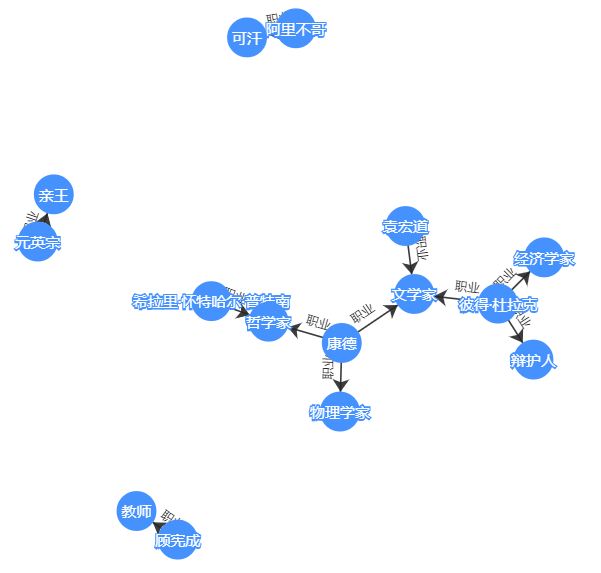
下面是以“职业”为关系查询条件所得出的结果。
总结一下
只是对几个月工作的梳理,大多数核心代码都改自现有的代码,所有的数据都来自于网络,与知识图谱相关的公开技术较少,我也只是尝试着做了一下,虽然很菜,也可以对大致的技术路线、流程有一个简单的了解,主要工作都是自然语言处理的内容。后期可以利用现在的知识图谱构建智能问答系统,实现从 what 到 why 的转换。
以下内容更新于 2020 年 3 月。
在毕业前收到了电子工业出版社和另一家出版社的写书邀请,我和电子工业出版社签订了写书合同,从还未毕业开始断断续续写作了一年的时间,因为自己的懒惰,加上内容中涉及到大量爬虫,而且爬目标网站是政府网站(不允许爬),另外 19 年网上时不时曝出某某程序员因爬虫而入狱的故事,出版社和我难免不会恐惧,我也正好找到了不再继续写下去的理由。
花了点时间把以前的程序,书籍已经写成的内容整理了一下,放在了 economic_audit_knowledge_graph 中,所有资料都在里面,希望能帮助到自然语言入门的小伙伴,我自己已经不做这个领域了!