微信公众号已经成为生活的一部分了,虽然里面有很多作者只是为了蹭热点,撩读者的 G 点,自己从中获得一些收益;但是不乏好的订阅号,像刘大的码农翻身、Fenng的小道消息、曹大的caoz的梦呓等订阅号非常值得阅读。
平时有时候看到一些好的公众号,也会不自觉去查看该公众号的历史文章,然而每次都看不完,下一次再从微信里面打开历史文章,又需要从头翻起。而且对于写了很多年的大号,每次还翻不到底。有一些平台提供了相关的服务,但是得收几十块钱的费用,倒不是缺几十块钱,主要是觉得这种没必要花的钱不值得去浪费。
网上搜如何爬微信公众号历史文章,大致给了三种思路,第一是使用搜狗微信搜索文章,但是好像每次能搜到的不多;第二是使用抓包工具;第三种是使用个人订阅号进行抓取。
简单来说就是使用程序来模拟人的操作,抓取公众号历史文章。首先登录微信公众号个人平台,期间需要管理员扫码才能登录成功。
def __open_gzh(self):
self.driver.get(BASE_URL)
self.driver.maximize_window()
username_element = self.driver.find_element_by_name("account")
password_element = self.driver.find_element_by_name("password")
login_btn = self.driver.find_element_by_class_name("btn_login")
username_element.send_keys(USERNAME)
password_element.send_keys(PASSWORD)
login_btn.click()
WebDriverWait(driver=self.driver, timeout=200).until(
ec.url_contains("cgi-bin/home?t=home/index")
)
# 一定要设置这一步,不然公众平台菜单栏不会自动展开
self.driver.maximize_window()
进入微信公众平台首页后,点击素材管理,然后点击新建图文素材,就会进入到文章写作页面,此时前面打开的微信公众平台首页就不需要了,可以将其关闭。
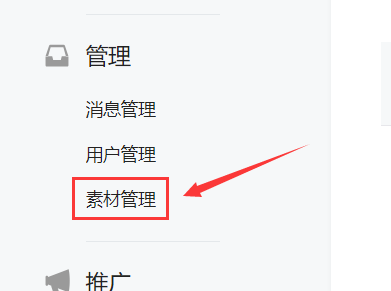
def __open_write_page(self):
management = self.driver.find_element_by_class_name("weui-desktop-menu_management")
material_manage = management.find_element_by_css_selector("a[title='素材管理']")
material_manage.click()
new_material = self.driver.find_element_by_class_name("weui-desktop-btn_main")
new_material.click()
# 关闭公众平台首页
handles = self.driver.window_handles
self.driver.close()
self.driver.switch_to_window(handles[1])
在文章写作页面的工具栏上面有一个超链接按钮,点击超链接即会弹出超链接编辑框,选择查找文章,输入自己喜欢的公众号进行查找,一般第一个就是自己想要的结果,点击对应的公众号,该公众号所有的文章就会通过列表的形式展现出来。
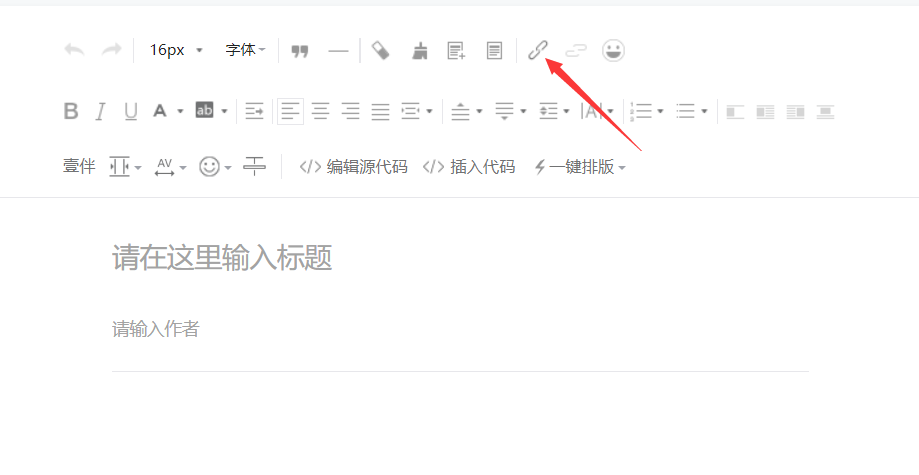
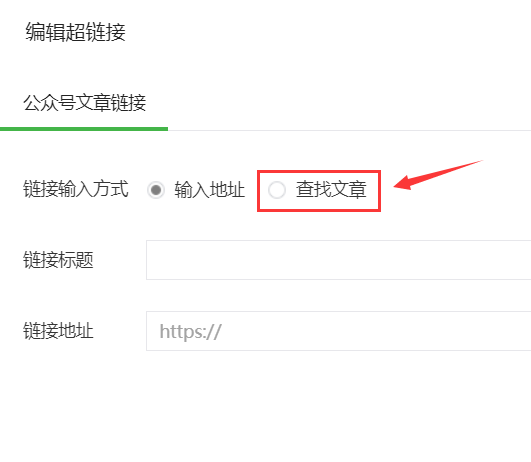
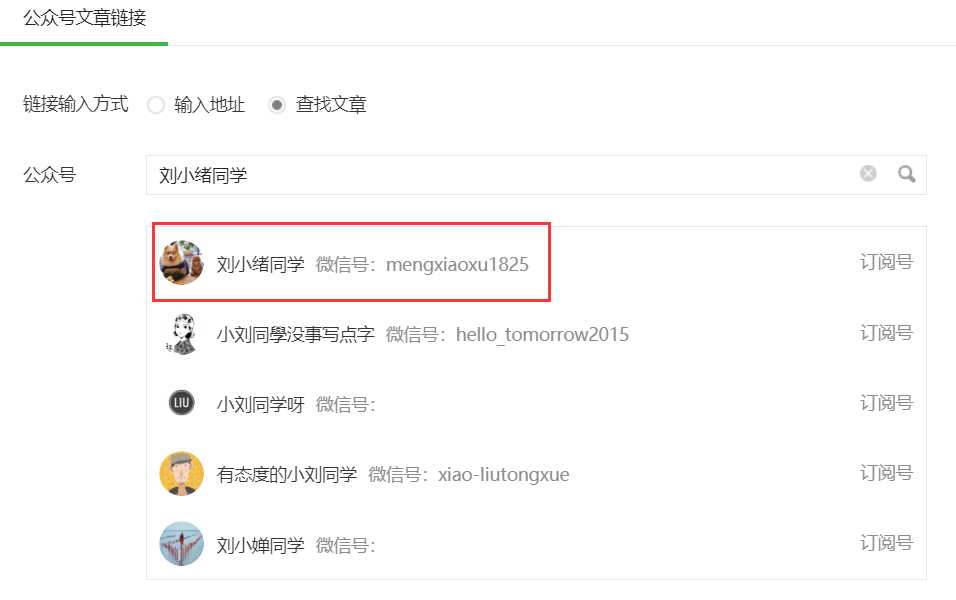
def __open_official_list(self):
# 超链接
link_click = self.driver.find_element_by_class_name("edui-for-link")
link_click.click()
time.sleep(3)
# 查找文章
radio = self.driver.find_element_by_class_name("frm_vertical_lh").find_elements_by_tag_name("label")[1]
radio.click()
# 输入查找关键字
search_input = self.driver.find_element_by_class_name("js_acc_search_input")
search_input.send_keys(OFFICIAL_ACCOUNT)
search_btn = self.driver.find_element_by_class_name("js_acc_search_btn")
search_btn.click()
# 等待5秒,待公众号列表加载完毕
time.sleep(5)
result_list = self.driver.find_element_by_class_name("js_acc_list").find_elements_by_tag_name("div")
result_list[0].click()
文章列表已经展现出来了,直接抓取每条文章超链接的信息即可,每抓取完一页就进入下一页,继续抓取文章列表信息,直到所有文章信息都抓取完毕。
def __get_article_list(self):
# 等待文章列表加载
time.sleep(5)
total_page = self.driver.find_element_by_class_name("search_article_result")\
.find_element_by_class_name("js_article_pagebar").find_element_by_class_name("page_nav_area")\
.find_element_by_class_name("page_num")\
.find_elements_by_tag_name("label")[1].text
total_page = int(total_page)
articles = []
for i in range(0, total_page-1):
time.sleep(5)
next_page = self.driver.find_element_by_class_name("search_article_result")\
.find_element_by_class_name("js_article_pagebar").find_element_by_class_name("pagination")\
.find_element_by_class_name("page_nav_area").find_element_by_class_name("page_next")
article_list = self.driver.find_element_by_class_name("js_article_list")\
.find_element_by_class_name(" my_link_list").find_elements_by_tag_name("li")
for article in article_list:
article_info = {
"date": article.find_element_by_class_name("date").text,
"title": article.find_element_by_tag_name("a").text,
"link": article.find_element_by_tag_name("a").get_attribute("href")
}
articles.append(article_info)
next_page.click()
return articles
至此,微信公众号历史文章的爬虫已经实现,其实整个过程只不过是用程序来模拟的了人类的操作。需要注意的是,程序不能设置太快,因为微信做了相关限制,所以设太快会在一段时间内无法使用文章查找功能;另外一点是使用选择器选择页面元素的时候,会有一些坑,而且我发现不同账号登录,有很少部分的页面元素虽然直观上是一样的,但是它的 html 代码有细微的差别。
这个小程序会用到selenium库,和chromedriver,前者直接pip install即可,后者自行下载;另外你还需要一个订阅号才行,本文只实现了关键的文章信息抓取,并没有进行文章信息的持久化存储,完整代码在这里。