参考内容:
许许多多的软件都有搜索文本的功能,这个搜索的过程其实就是一个字符串匹配的过程。由此我们可以提出来一个问题。
给你两个字符串s和p(p的长度不超过s的长度,并且p和s都不是空串),请问s中是否包含p,若包含请给出第一次包含的开始位置?比如:
s="hello, string",p="str",那么s包含p;- 比如
s="github",p="str",那么s不包含p。
暴力求解
分析题目我们很容易就能想到解决方法。设置两个指针,分别为i和j,并且将两个指针都初始化为0。对比s[i]和p[j]的值,如果两个值相等,那么同时将i和j移动到下一个位置。否则i回退到1,j回退到0,继续上述过程。如果在下一次匹配过程中还是出现了不想等的字符,那么i回退到2,j回退到0,继续......。直到某次匹配中,j达到越界位置,那么就可以判定s包含p,此时i的值即开始位置,否则s就不包含p。
#include<bits/stdc++.h>
using namespace std;
int main()
{
char p[300], s[300];
cin>>p>>s;
int len_p = strlen(p);
int len_s = strlen(s);
if(len_p > len_s){
cout<<-1<<endl;
return 0;
}
int j = 0, ans = -1;
for(int i = 0; i < len_s; i++){
if(p[j] == s[i]){
if(j == 0){
ans = i;
}
if(j == len_p-1){
break;
}
j++;
} else {
j = 0;
ans = -1;
}
}
if(j == len_p-1){
cout<<ans<<endl;
} else {
cout<<-1<<endl;
}
}
当然,你也可以使用 C 语言所提供的库函数进行实现,比如strstr、strcmp、strncmp等,此处不再赘述相关实现。
优化分析
我们来看一下s="aaaaaaaaab"和p="aaab"的匹配过程。
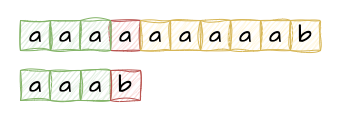
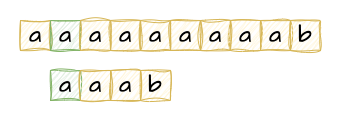
当我们发现第一次匹配失败时,我们只能选择下一个开头,重新从开头继续匹配。此时指向s的指针就会回退,并且此前已经匹配的部分将全部丢弃,因此暴力求解的方法是很低效的。
我们肉眼可以直观的看到如果匹配失败了,并不需要全部回退,也就是我们可以借助此前匹配过程留下的信息,帮助我们加速匹配过程。很明显能加速匹配过程的办法就是尽量少回退甚至不回退指针,那么我们一起来探究一下如何在少回退指针的前提下,还能保证不错过正确答案。
因为我们是在s中寻找是否存在p,即当前i指针前面的字符都已经对比过了,所以理论上我们是可以不回退i指针的,那么保证i指针不回退了,又如何调整回退j指针的规则呢?
- 肯定
j指针需要回退 - 需要保证
j指针回退后,s[i]和p[j]之前的所有字符都是匹配的 - 指针
j不能因为回退少了,导致我们错过正确答案
下面我们举几个例子。

那如果已经匹配的部分存在多个前缀和后缀匹配的情况怎么办呢?
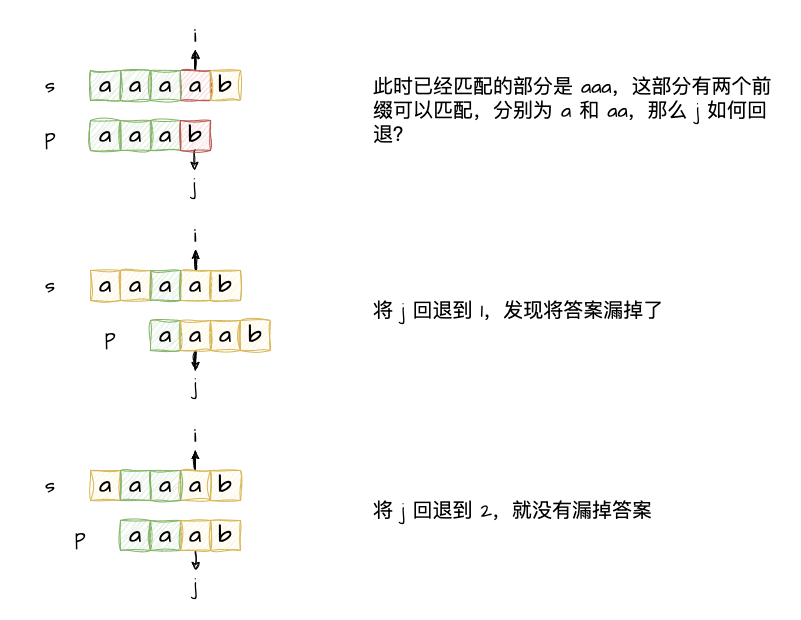
总结一下:在保证指向s的指针不回退的时候,我们需要找到前面已经匹配部分的前后缀最大匹配长度,而且这个前后缀最大匹配长度是可以直接通过p的值计算出来的(即next数组)。