文章内容是刘欣大大(《码农翻身》作者,公众号:码农翻身)的直播课内容,主要是了解一下分布式文件系统,学习FastDFS的一些设计思想,学习它怎么实现高效、简洁、轻量级的一个系统的
FastDFS分布式文件系统简介
国内知名的系统级开源软件凤毛菱角,FastDFS就是其中的一个,其用户包括我们所熟知的支付宝、京东商城、迅雷、58同城、赶集网等等,它是个人所开发的软件,作者是余庆。
我们已经进入互联网时代,互联网给我们的生活带来便捷的同时,也给我们带来了诸多挑战。

对于海量文件的存储,一个机器不够,那么就用多台机器来存储。
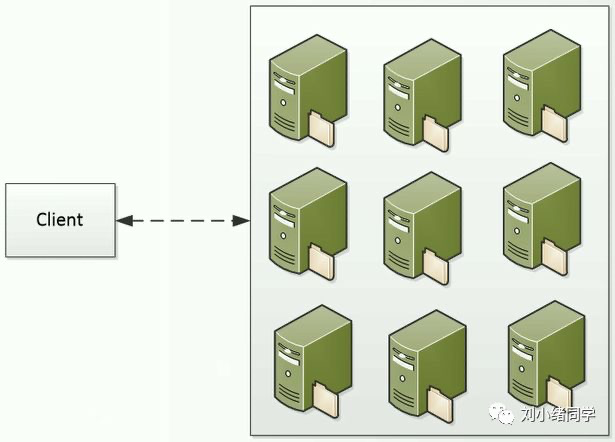
如果一个文件只存储一份,那么如果存储这个文件的机器坏掉了,文件自然就丢失了,解决办法就是将文件进行备份,相信大多数人都有备份重要文件的习惯。FastDFS也是如此,为了防止单点的失败,肯定是需要冗余备份的。
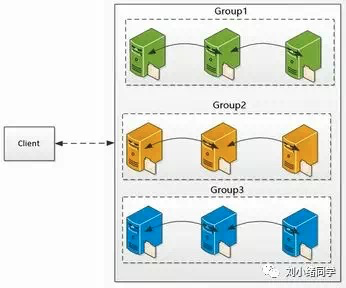
FastDFS把应用服务器分为若干个组,每一组里面可以有多台机器(一般采用3台),每一台机器叫做存储服务器(storage server)。同一组内之间的数据是互为备份的,也就是说用户把文件传到任一服务器,都会在同组内其它两个服务器进行备份,因此一个组的存储空间大小是由该组内存储空间最小的那台机器是一样的(和木桶原理一样)。为了不造成存储空间的浪费,同一个组内的三台机器最好都一样。
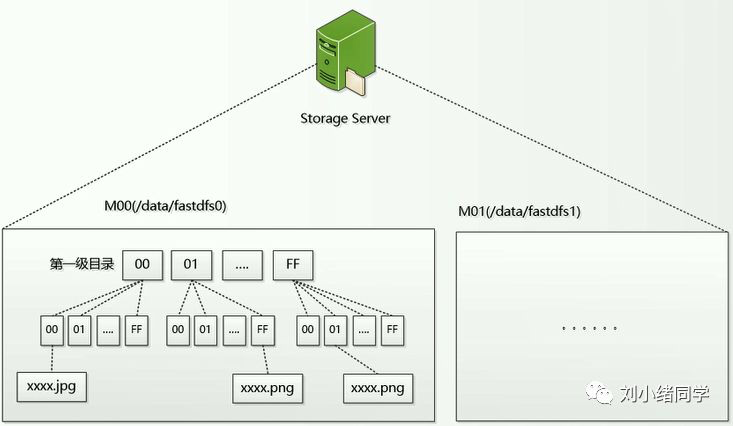
每个存储服务器(storage server)的存储就够又是怎样的呢?展开来看,它可以分为多个目录,每个目录以M开头,用00、01、02......来划分,一般无需划分这么多目录,只用一个目录就可以了。
在每个根目录下面又划分了两级目录。如图所示,在/data/fastdfs0下又划分出两级目录,每一级有256个目录,这样算下来总共就有65535个目录了。存储文件时,就是通过两次哈希来确定放在哪一个目录下面。
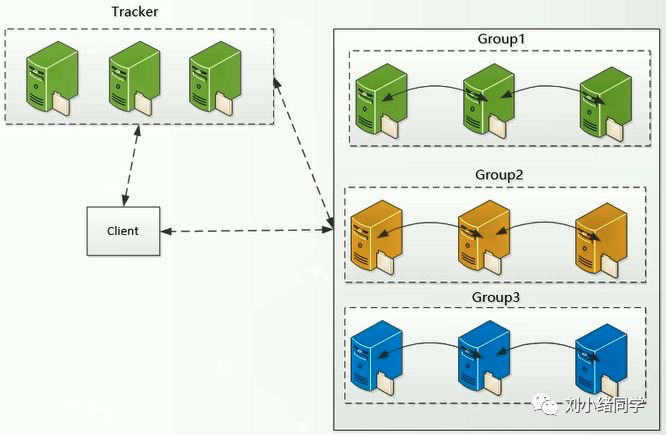
那么问题就来了,有这么多组,到底该选择哪个组的服务器进行存储呢?或者说,访问的时候到底访问哪一个组呢?
FastDFS提供的解决思路是引入一个跟踪服务器(tracker server),它用于记录每一个组内的存储服务器信息,存储信息是每个storage主动回报给tracker,有了这些信息之后,tracker就可以做调度工作了,看看谁的存储空间大,就把文件放过去。
FastDFS的特点
- 组与组之间是相互独立的
- 同一个组内的storage server之间需要相互备份
- 文件存放到一个storage之后,需要备份到别的服务器
- tracker之间是不交互的
- 每个storgae server都需要向所有的tracker去主动报告信息
- tracker与tracker之间是不知道彼此的存在的
如何上传文件
为方便下载文件的理解,这里假设上传的文件为:Group1/M00/00/0C/wKjGgVgbV2-ABdo-AAAAHw.jpg
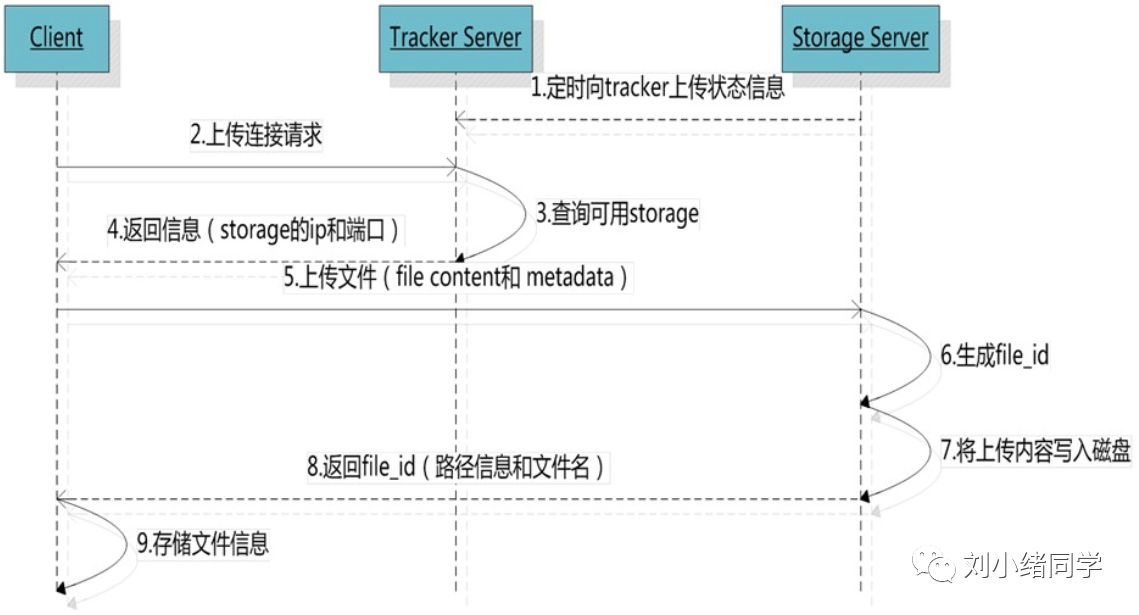
如下面的时序图可以看到客户端是如何上传文件到服务器的。首先client向tracker发送上传链接请求,然后由tracker进行调度,查询可用的storage,并把该storgae对应的ip和端口发送给client;拿到了存储服务器信息,client就直接将文件上传到storage即可;storage会生成新的文件名再写入到磁盘,完成之后再把新的文件信息返回给client,client最后把文件信息保存到本地。需要注意的是,storage会定时向tracker回报信息。
如何进行选择服务器
- tracker不止一个,客户端选择哪一个做上传文件?
- tracker之间是对等的,任选一个都可以
- tracker如何选择group?
- round robin(轮询)
- load balance(选择最大剩余空间group上传)
- specify group(制定group上传)
- 如何选定storage?
- round robin,所有server轮询使用(默认)
- 根据ip地址进行排序选择第一个storage(ip地址最小者)
- 根据优先级进行排序(上传优先级由stoage来设置,参数为upload_priority)
- 如何选择storage path
- round robin,轮询(默认)
- load balance,选择使用剩余空间最大的存储路径
如何选择存放目录
- 选定存放目录?
- storage会生成一个file_id,采用Base64编码,字段包括:storage ip、文件创建时间、文件大小、文件CRC32校验和随机数
- 每个存储目录下面有两个256 * 256个子目录,storage会按文件file_id进行两次hash,然后将文件以file_id为文件名存储到子目录下
需要注意的是:file_id由cilent来保存,如果没有保存,你就不知道你上传的文件去那里了
Storage server之间的文件同步
- 同一组内的storage之间是对等的,文件上传、删除等操作可以在任意一台storage上进行
- 文件同步只在同组内的stroage之间进行,采用push方式,即源服务器同步给目标服务器
- 源头数据才需要同步,备份数据不需要再次同步,否则就构成环路了
- 新增一台storage时,由已有的一台storage将已有的所有数据(包括源头数据和备份数据)同步给该新增服务器
Storage的最后最早同步被同步时间
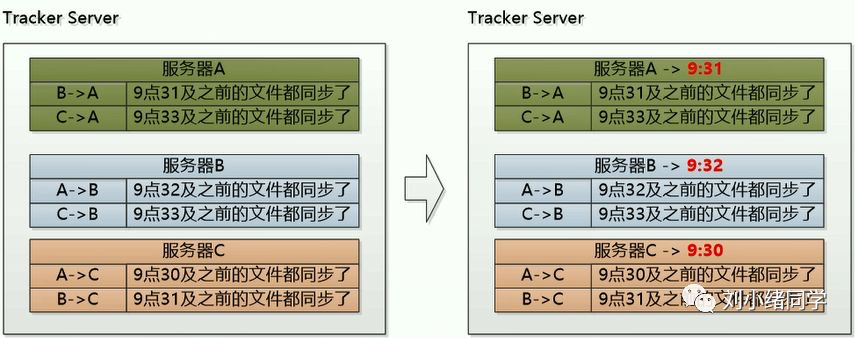
这个标题有一些拗口,现在有三台服务器A、B、C,每个服务器都需要记录其他两台服务器向自己进行同步操作的最后时间。比如下图中的服务器A,B在9:31向A同步了所有的文件、C在9:33向A同步了所有的文件,那么A服务器的最后最早被同步时间就是9:31。其他两个服务器也是一样。
最后最早被同步时间的意义在于判断一个文件是否存在于某个storage上。比如这里的A服务器最后最早被同步时间为9:31,那么如果一个文件的创建时间为9:30,就可以肯定这个文件在服务器A上肯定有。
Stroage会定期将每台机器的同步时间告诉给tracker,tracker在client需要下载一个文件时,要判断一个storage是否有该文件,只需要解析文件的创建时间,然后与该值作比较,若该值大于创建时间,说明storage存在这个文件,可以从该storage下载。
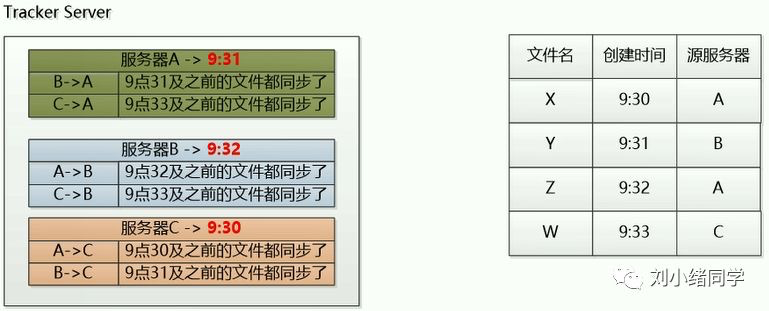
但是这个算法有缺陷,比如下面的情况:W文件的创建时间是9:33,服务器C已经把9:33之前的文件都同步给B了,因此B服务器里面其实已经有W文件了,但是根据最后最早被同步时间,会认为B中没有W文件。因此这个算法虽然简单,但是牺牲了部分文件。
如何下载文件
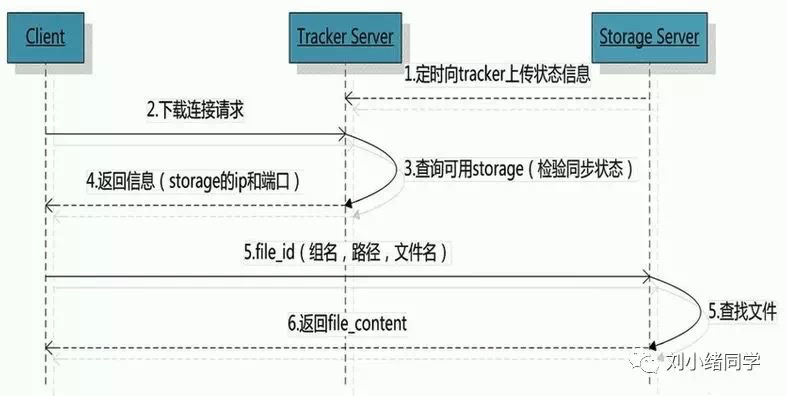
首先由client发送下载连接请求,请求的东西本质上就是Group1/M00/00/0C/wKjGgVgbV2-ABdo-AAAAHw.jpg;tracker将查询到的可用storage server(按下文的四个原则进行选择)的ip和端口发送给client;现在client有本地保存的文件信息,也有服务器的地址和端口,那么直接访问对应的服务器下载文件即可。
如何选择一个可供下载的storage server
共下面四个原则,从上到小条件越来越宽松
- 该文件上传到的源storage(文件直接上传到该服务器上)
- 文件创建时间戳 < storage被同步到的文件时间戳,这意味着当前文件已经被同步过来了
- 文件创建时间戳 = storage被同步到的文件时间戳,并且(当前时间-文件创建时间戳)> 一个文件同步完场需要的最大时间(5分钟)
- (当前时间 - 文件创建时间)> 文件同步延迟阀值,比如我们把阀值设置为1天,表示文件同步在一天内肯定可以完成
FastDFS的使用
用户通过浏览器或者手机端访问web服务器,web服务器把请求转发给应用服务器,应用服务器收到请求后,通过fastDFS API和FastDFS文件系统进行交互。但是这么设计会造成应用服务器的压力,因为上传和下载都经过应用服务器。
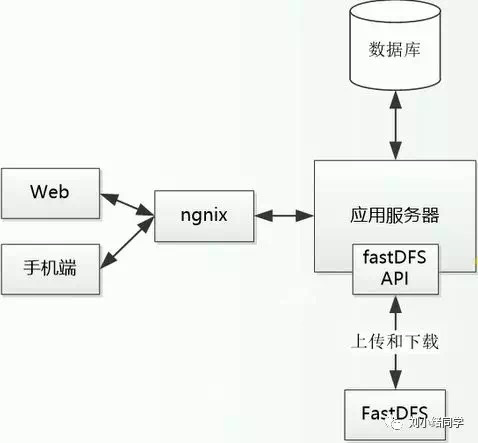
为了避免应用服务器压力过大,可以让客户端直接使用Http访问,不通过应用服务器。
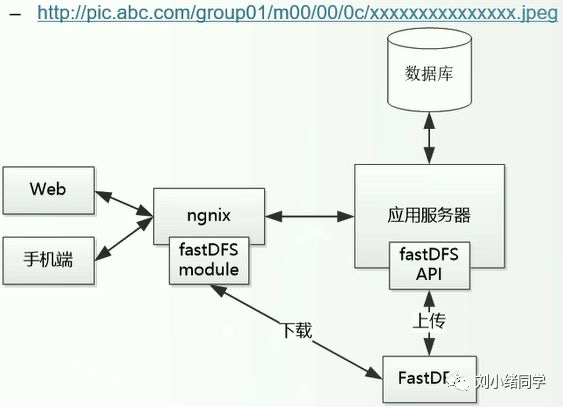
FastDFS其他内容
防止盗链
为了防止辛辛苦苦上传的文件被别人盗去,可以通过给URL设置token来解决。FastDFS的防止盗链配置如下:
# 是否做tokrn检查,缺省值为false
http.anti\_steal.check\_token=true
# 生成token的有效时长/秒
http.anti\_steal.token\_ttl=900
# 生成token的密钥,尽量设置长一些
http.anti\_steal.secret\_key=@#$%\*+\*&amp;!~
FastDFS生成token策略为:token = md5(文件名,密钥,时间戳)

合并存储
- 海量小文件的缺点
- 元数据管理低效,磁盘文件系统中,目录项、索引节点(inode)和数据(data)保存在介质不同的位置上
- 数据存储分散
- 磁盘的大量随机访问降低效率(小文件有可能这个在这个磁道,那个在那个磁道,就会造成大量的随机访问,大量小文件对I/O是非常不友好的)
- FastDFS提供的合并存储功能
- 默认大文件64M
- 每个文件空间称为slot(256bytes = slot = 16MB)
也就是说对于小文件,FastDFS会采用把多个小文件合并为一个大文件的方式来存储,默认建一个大小为64M的大文件,然后再分成多个槽,最小的槽是256bytes,因此如果一个文件小于256bytes,那么它也会占256bytes的大小。就好像我们在医院见到的中药柜子一样,每个抽屉里面再分成多个小格子,根据药材包的大小来选择不同大小的格子。
没有合并时的文件ID

合并时的文件ID

此处不再深入探讨存储合并的机制,因为它带来了一系列新的问题,比如同步时不仅需要记录大文件的名称,还需要进入小文件的名称,一下子变得麻烦多了;原来空闲空间管理直接通过操作系统就能计算出来,但是现在不行了,因为是创建了一个64M的块,这个块里面还有空闲空间,计算起来就很麻烦了。
总结
- FastDFS是穷人的解决方案
- FastDFS把简洁和高效做到了极致,非常节约资源,中小型网站完全用得起